Các thuật toán unsupervised classification cho người mới bắt đầu + chút ứng dụng thực tế
Mình đang có một số bài toán của công ty cần giải quyết cần research về vụ này, sẵn tiện viết ra để vừa nhớ vừa chia sẻ với các bạn luôn.

Bài toán của mình cũng đơn giản và khá tiêu biểu: một số đối tượng có các features A, B, C, D, E, F, cần classify các đối tượng này thành một số group nào đó để các đội vận hành xử lý tiếp. Bài toán thì không nói ra cụ thể được, anh em thông cảm Nhưng điểm chung là các đối tượng này chưa từng được phân nhóm (clustering), tức là không có nhãn sẵn (label). Bạn phải đi tìm nhãn cho chúng.
Tiếp, mình chỉ viết mấy cái mình đã đụng, đã làm thôi nhé, còn mấy cái chưa xài thì không dám chém. Reference của mình là từ bài viết này:https://towardsdatascience.com/the-5-clustering-algorithms-data-scientists-need-to-know-a36d136ef68 112. 5 cái lận, mà mình viết 2 thôi.
K Mean
K Mean kiểu như là thuật toán phân loại nổi tiếng nhất, ở đâu cũng thấy, mấy môn học ML, data cơ bản thấy người ta cũng dạy nhiều. Bản thân team mình cũng dùng vài lần cho một số bài toán và thấy nó khá đúng, outcome đưa ra khá hài lòng. Bạn có thể xem giải thích chi tiết về K Mean và các nền tảng toán của nó 93, mình thì không hiểu nên thôi bỏ qua hihihi.
Về ứng dụng thực tế thì mình từng dùng K Mean thành công để phân loại khách hàng và phân loại nhóm đối tượng để bắn coupon cho hiệu quả (ví dụ: team marketing có 3 loại coupon cần gửi cho khách, bạn có thể dùng K Mean để tìm ra 3 nhóm này trong tập khách hàng của bạn dựa theo số đơn hàng, loại món, giờ mua hàng, tần suất mua hàng).
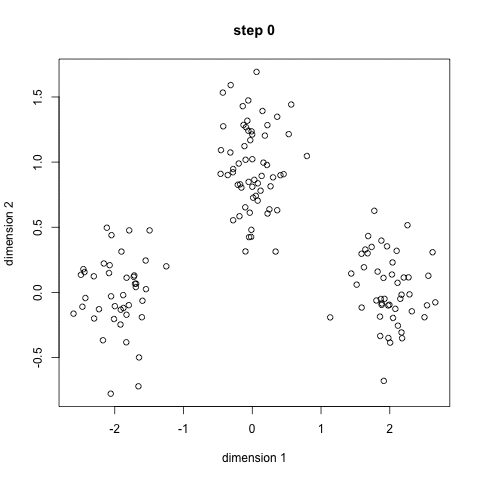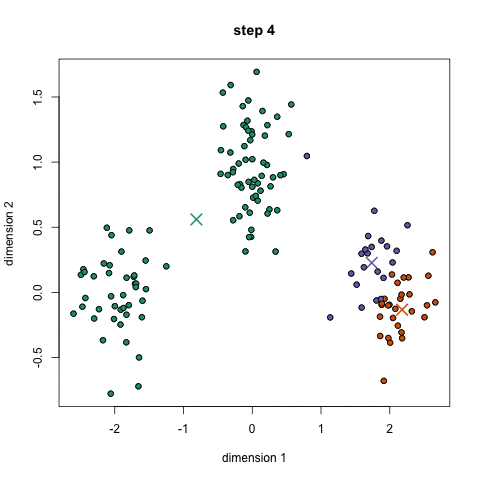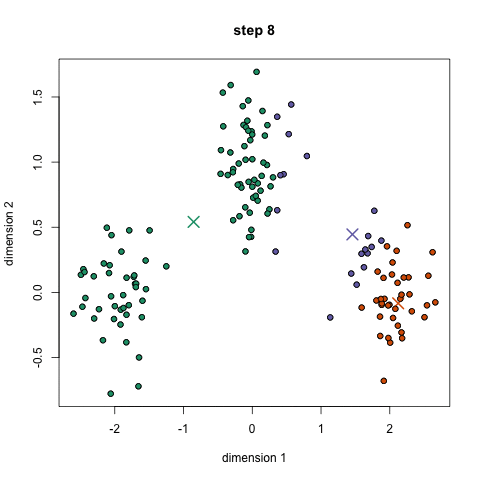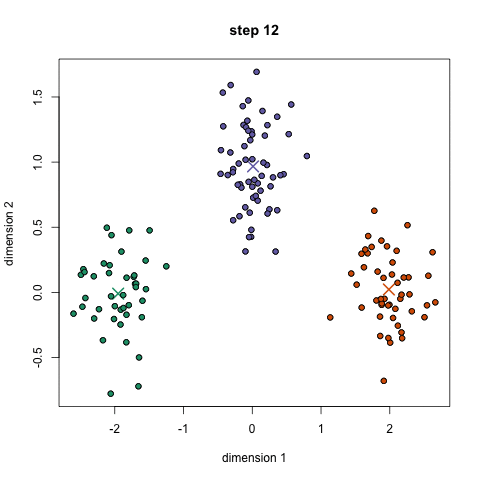
K Mean hoạt động theo cách cơ bản như sau: giả sử bạn có 1 loạt các điểm X, Y trong không gian.
Bước 1: Thuật toán sẽ tạo ra một số điểm bất kì trong không gian, ví dụ bạn muốn chia thành 3 nhóm thì k = 3. 3 điểm này gọi là centroids. Bước 2: Với mỗi điểm dữ liệu, nó sẽ tạm thời được phân vào một nhóm (cluster) dựa theo khoảng cách của điểm dữ liệu tới điểm k gần nhất. Bước 3: Với mỗi cluster này, tính mean của các điểm rồi gán điểm mean này là centroids mới Bước 4: Người ta sẽ lặp đi lặp lại bước 2 và 3 cho tới khi kết quả không còn thay đổi nhiều.
Bạn có thể xem được các bước này trong hình dưới.
Một cái hạn chế của K Mean là bạn buộc phải định nghĩa cho thuật toán biết bạn muốn tìm ra bao nhiêu nhóm. Bạn phải biết trước số này. Có một cách mình hay dùng để chọn số K, đó là thuật toán Elbow. Xem chi tiết ở đây, 61 còn bên dưới là một biểu đồ của mình để chọn K, thấy nó gấp khúc ngay K = 2 nên mình chọn phân làm 2 nhóm.

Code để implement K Mean thì dễ lắm. Cứ lấy một dataframe X với một loạt các features cần phân loại bỏ vào là xong.
# Number of clusters
kmeans = KMeans(n_clusters=2)
# Fitting the input data
kmeans = kmeans.fit(X)
# Getting the cluster labels
labels = kmeans.predict(X)
# Centroid values
centroids = kmeans.cluster_centers_
Với K Mean, nhớ cẩn thận dữ liệu NULL, dữ liệu sai, hoặc các nhóm quá lệch nhau. Có thể nó sẽ cho ra kết quả rất khác nhau đấy.
Mean Shifting
Thuật toán này cũng có thể giải những bài toán tương tự như trên với phân bố dữ liệu không có gì quá đặc biệt. Mình sẽ dùng Mean Shifting (MS) khi K Mean cho ra kết quả không phù hợp hoặc có gì đó lạ lạ so với thực tế, hoặc giải pháp elbow không đưa ra được một con số K đủ tốt để chọn. Các bạn có kinh nghiệm nào khi dùng MS thì chia sẻ thêm nhé.
Trong Mean Shift, bạn cũng chọn 1 số điểm để bắt đầu. Các điểm này sẽ dần dần dịch chuyển về khu vực có mật độ data dày hơn, như hình bên dưới. Bạn thấy là mấy cái chấm màu đen không dịch ra xa về phía khu vực có nhiều khoảng trống mà toàn dịch vào tâm của các điểm dữ liệu.

Điều này có được là do chúng dịch chuyển một khoảng = mean của các điểm nằm trong một khu vực mà bạn muốn xét (khu vực này gọi là window). Cũng vì phương thức dịch chuyển (shift) dựa vào mean nên thuật toán này mới có cái tên như trên. Sau khi lặp đi lặp lại nhiều lần, những điểm nằm trong cùng window sẽ được nhóm thành 1 nhóm.
MS có cái hay là bạn không cần chọn trước số nhóm cần phân loại. Thuật toán có thể tìm được số nhóm đó cho bạn luôn vì chúng sẽ dịch chuyển tự động.
Cái khó của MS là chọn window - bán kính vùng quét để tính mean - là bao nhiêu. Mình hiện đang dùng hàm estimate_bandwidth của SkLearn để chọn thông số này.
bandwidth = estimate_bandwidth(your_dataset, quantile=0.2, n_samples=500)
ms = MeanShift(bandwidth=bandwidth, bin_seeding=True)
ms.fit(X)
labels = ms.labels_
cluster_centers = ms.cluster_centers_
labels_unique = np.unique(labels)
n_clusters_ = len(labels_unique)
#add the label back to the dataframe
df_run['meanshift_grouping_label'] = labels
print("number of estimated clusters : %d" % n_clusters_)
Đang thấy có cái Agglomerative Hierarchical Clustering khá thú vị, để mình thử rồi có gì sẽ chia sẻ với các bạn trong bài viết mới.